Ontotext Delivers Semantic Publishing Solutions to the World’s Largest Media & Publishing Companies

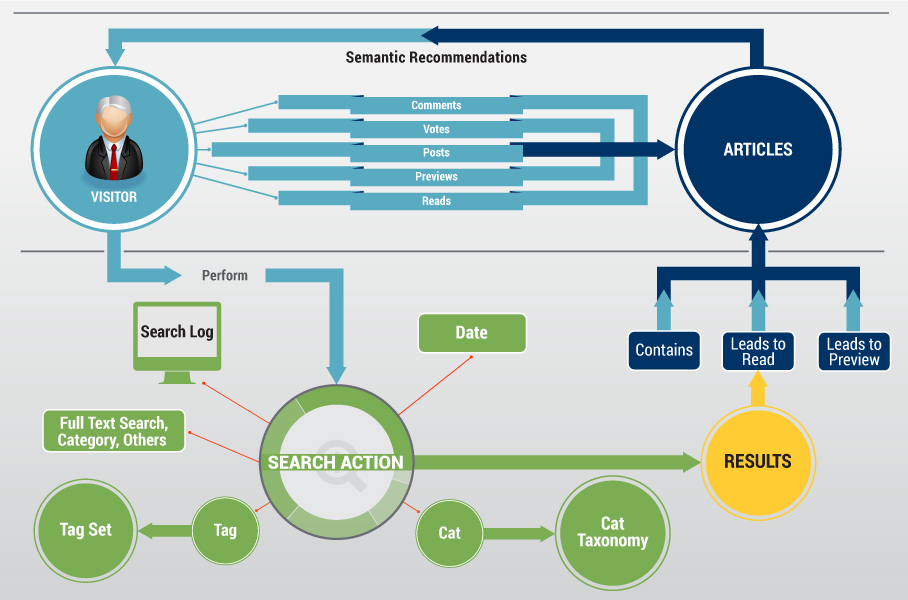
Washington DC (PRWEB) August 27, 2014 -- Ontotext Media & Publishing, a division of Ontotext headquartered in Sofia, Bulgaria with offices in London and Washington, DC recently expanded its solution to enable publishers to automatically deliver personalized recommendations based on semantic models, user behavior, profiles and content based information.
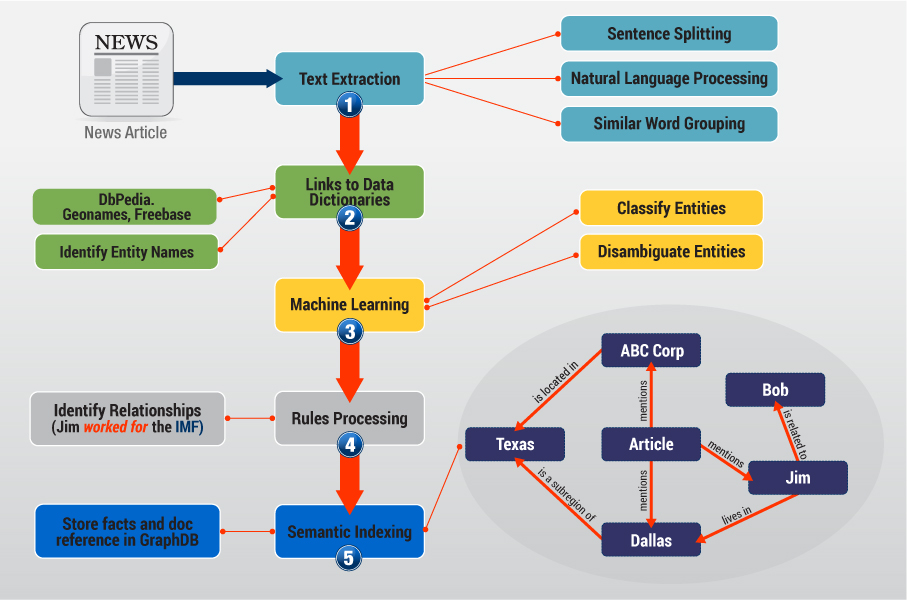
For years, Ontotext Media & Publishing has provided solutions that help publishers enrich content using a blend of text mining, named entity recognition, content categorization, concept extraction and more. These solutions include data management for billions of statements, dynamically assembled webpages and content curation, providing authors with unprecedented 'fine-grained' understanding of their content.
In their latest release, Ontotext Media & Publishing now offers Semantic Recommendations delivering highly targeted messages, related articles and advertisements based on contextual understanding. “Semantic Recommendations was designed to serve the needs of media and publishing companies interested in creating a world class user experience replete with personalized recommendations driven from enriched data and user behavior,” reports Borislav Popov, General Manager of Ontotext Media & Publishing. “But this solution works for any company challenged by large amounts of unstructured data. Organizations are realizing the value of blending concept extraction with classification and semantic technology to deliver a unique user experience. This solution combines past behavior with enriched content to deliver real time recommendations. It is unique since it scales to handle hundreds of queries per second while large database updates occur simultaneously – all within a high availability replication cluster proven to work in the most demanding media and publishing environments. Scientific and educational publishers can benefit from this as well.”
The complete solution includes a content layer, services layer and UI layer. The services layer has five major modules: Search & Analytics, Semantic Enrichment, Data Management, Continuous Adaptation and the newest set of services for Semantic Recommendations. Search & Analytics includes all types of search (semantic, faceted, full-text, hybrid) with analysis and trending. Semantic Enrichment includes services for text mining, named entity recognition and the disambiguation of entities. Data Management has tools for ingestion, normalization, annotation and curation. Continuous Adaptation allows users to dynamically enrich content, retrain the text mining algorithms, and manage the text-mining pipeline – all while they monitor quality assurance. Now this suite has been extended to include Semantic Recommendations.
About Ontotext
Ontotext provides a complete set of semantic technology transforming how organizations identify meaning across massive amounts of unstructured data. Ontotext blends text mining, powerful SPARQL queries, semantic annotation and semantic search with an RDF graph database (GraphDB™) that infers new meaning at scale. Today, Ontotext is used to power the world’s largest media websites and support knowledge management applications using tens of billions of semantic facts in publishing, healthcare, life sciences, government, museums and archives. Ontotext technology delivers highly relevant search results for improved decision making – all in real time.
Ontotext also just released “Ontotext S4”, The Self Service Semantic Suite allowing developers to build text mining and semantic applications in the cloud. S4 includes text mining, reliable access to Linked Open data (Freebase, DBpedia, GeoNames) to enrich entities extracted from text, a set of tools for developers and GraphDB™. S4 is available in a hosted environment with a pay-as-you-go model at low cost allowing small and mid-size businesses to use enterprise hardened technology at a fraction of the cost. Applications built using S4 can be deployed in the cloud or on premise. To get started, visit the S4 website. Try it for free!
Ontotext Media & Publishing incorporates GraphDB™ as its underlying foundation for discovery but extends far beyond this by combining a text mining pipeline that extracts concepts and entities from free flowing text, stores them in GraphDB™ and includes applications for semantic analysis of trends, content curation and search & discovery.
To learn more about other Ontotext products and solutions for Life Sciences, Compliance & Document Management, Cultural Heritage and our complete Semantic Platform including the new release of GraphDB™ 6.0, visit Ontotext.com.
Contact Info and Websites
Tony Agresta
Ontotext USA
tony.agresta(at)ontotext(dot)com
443-253-6810
Brad Bogle
Ontotext USA
brad.bogle(at)ontotext(dot)com
703-431-7567
40550 Banhsee Drive
Leesburg, Virginia 20175
Borislav Popov
Ontotext
borislav.popov(at)ontotext(dot)com
+359 2 974 61 60
Polygraphia Office Center fl.4,
47A Tsarigradsko Shosse,
Sofia 1124, Bulgaria
Ontotext Website
S4 Website
Twitter: @ontotext
Tony Agresta, Ontotext USA, http://www.ontotext.com, +1 443-253-6810, [email protected]
Share this article