CES 2019: PQ Labs to Disrupt AI Chips and GPUs, Enabling 199X Times Acceleration on Billions of Existing Devices Without a Hardware Upgrade
A Self-driving AI task running on a 0.9GHz CPU processor delivers 76% AI computing power of a nVidia Titan X (or 1080Ti) GPU, achieving the same object detection accuracy

LAS VEGAS, Jan. 10, 2019 /PRNewswire-PRWeb/ -- Running AI tasks without a GPU or AI chips can actually be faster? That seems to be impossible for decades until 2019 when PQ Labs demonstrated a jaw-dropping AI solution to surprise every visitors in the CES tech show.
By embedding a 0.9GHz processor into a Lego car, the toy acquires Artificial Intelligence skills instantly to runs self-driving AI tasks such as detecting objects or obstacles. In the past, the toy would have to carry a large computer case with high graphics card installed in order to have such AI computing power.
The Lego car neural network runs at 512x256 resolution, and can detect 20 classes (car, person, dog, cat, helicopter, motorbike, fruits, football, etc). The neural network only uses 10% of the CPU time while achieving the same accuracy of Tiny Yolo network. No neural network quantization is used yet. The next version with quantization technique will make the neural network run even faster.
*Unfolding the technology via an alternative path other than GPU optimization.
For historical reasons, the whole AI industry, and academics researches are built upon the graphics card programming model (specifically NVIDIA GPU card, while AMD GPU lacks such software/algorithm functionality). There are other AI chips follow suit, but they are all using similar AI models and optimization strategy.
"The AI technology tree may be unfolded in a wrong way or at least there is another alternative tech path to be explored in order to achieve better AI results. And this is where PQ Labs comes into play," says Frank Lu, PQ Labs CEO and inventor of MagicNet
MagicNet is the Answer
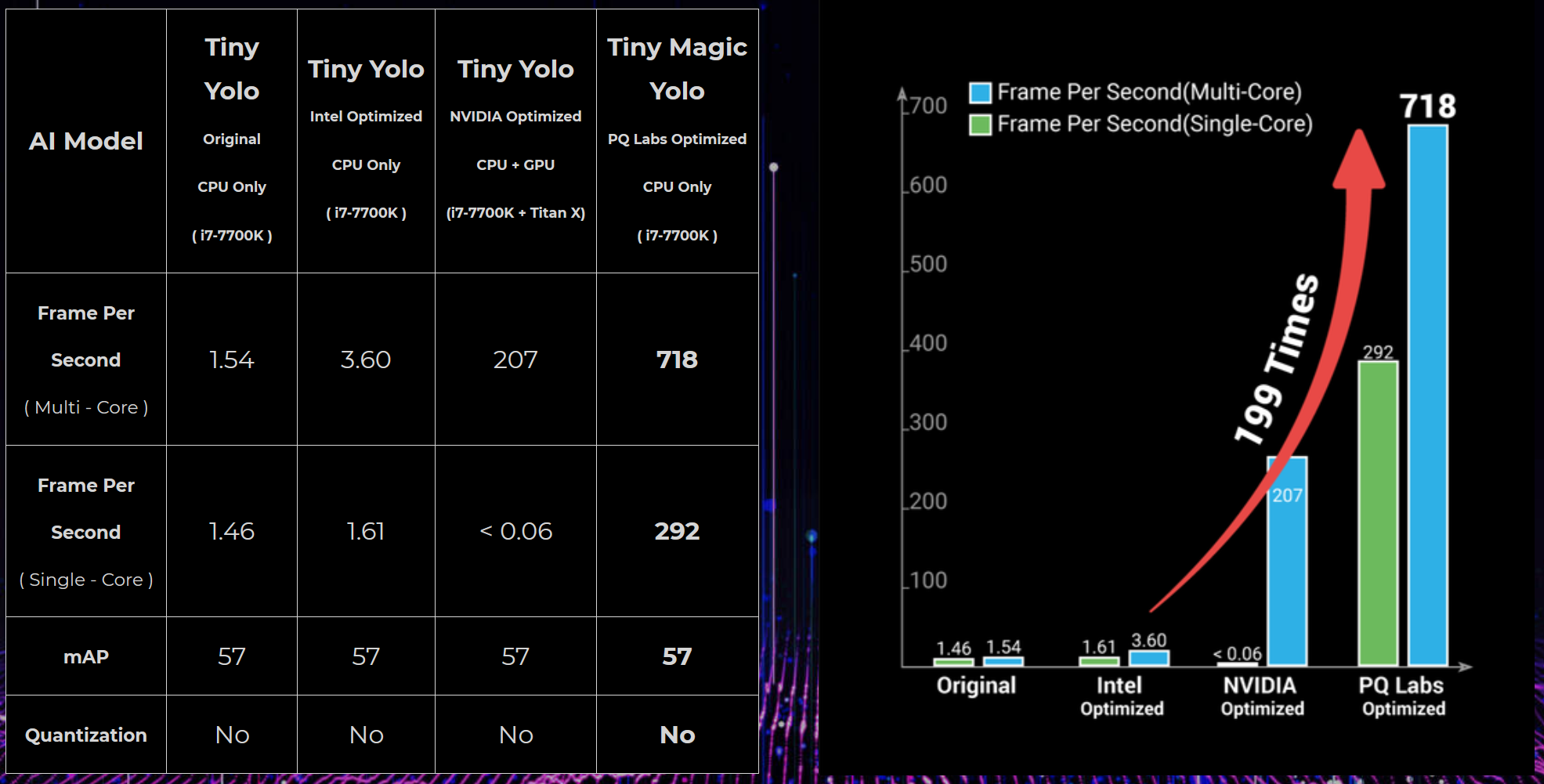
The new technology is called "MagicNet". It is unbelievably fast, running object detection at 718 FPS on an i7 Intel processor without the loss of accuracy compared with Tiny Yolo running 3.6 FPS on the same CPU, achieving 199X times acceleration. It is even 3.5X faster than GPU accelerated Tiny Yolo (207 fps running on Titan X or 1080 Ti).
MagicNet is designed and developed from the ground up starting from the fundamentals of deep learning mathematics. All math operations are redesigned and re-implemented into a library called "Magic-Compute", replacing the need of nVidia Cuda, Cudnn or Intel MKL and runs significantly faster. For example, "convolution" operations (the building block of all deep learning models) are replaced by Magic-Convolution to enjoy significant performance boost.
The speedup of "MagicNet" also comes from its unique AI backbone model. The backbone runs faster than efficient models such as MobileNet V2, ShuffleNet V2 with higher accuracy. By replacing the backbones of Yolo or SSD with MagicNet, the new networks: Magic-Yolo or Magic-SSD can run 199x times faster than the original versions.
"MagicNet" is born to be different. The current AI industry and academic researches are still following the same training procedure defined since the very early days of deep learning. It relies heavily on tuning/training ImageNet classification model and then does transfer learning on other tasks such as object detection, etc. This is the way how deep learning 1.0 worked and worked so well in the past. However, tuning ImageNet classifications may not be the best way to do it, sometimes better classification result may hurt the accuracy of other tasks. MagicNet uses a different training procedure to solve the problem.
*Compatible with existing models and frameworks
MagicNet is innovative and unbelievably faster, but how about existing models trained in TensorFlow, Caffe, Pytorch, etc. Time and money have already spent on these models and people want to simply run them faster. MagicNet is backward compatible with existing models and makes them run faster without re-training or coding.
For more details of PQ Labs MagicNet AI technology, please visit website: http://www.pqlabs.ai
SOURCE PQ Labs


Share this article