
SAN MATEO, Calif., Sept. 27, 2018 /PRNewswire-PRWeb/ -- Since the launch of Gengo.ai, the company's crowdsourcing platform for AI/ML training data, Tokyo-based Gengo has experienced a surge in demand for high volumes of well-annotated text and audio data. Today, Gengo announced that it has processed more than one billion words to date.
Gengo.ai, which provides multilingual training data used for the development of artificial intelligence (AI) and machine learning (ML) applications, has built a crowdsourced network of 25,000+ certified native speakers to deliver high-scale multilingual services in 37 languages.
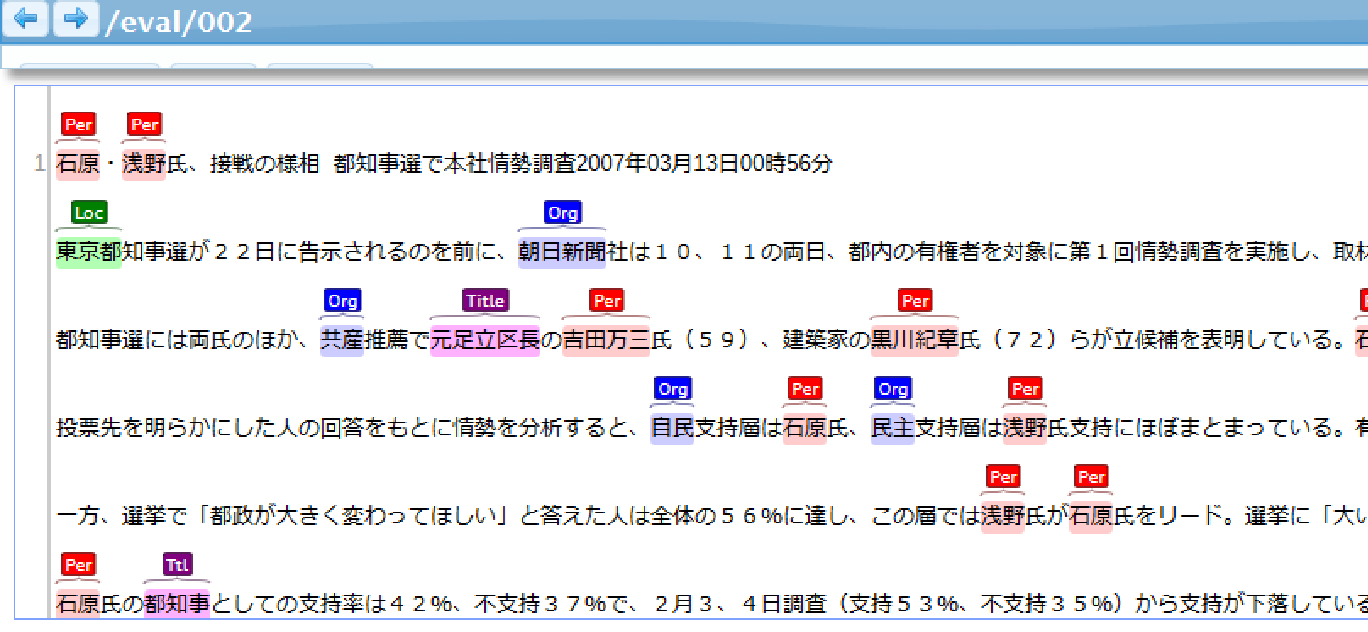
The billionth-word threshold was surpassed during a project with Basis Technology Corp., a software company that specializes in applying artificial intelligence techniques to understand documents and unstructured data written in different languages. The billionth word was "朝日新聞", which translates to Asahi Newspaper, one of the five national newspapers in Japan.
The Gengo.ai expert crowd has been undertaking some interesting projects recently, some of which depart from Gengo's roots as a translation company. In this case, the billionth word was actually sourced from an entity annotation project. For this particular project, Gengo was given more than 1,700 files containing Japanese news articles. Basis Technology partnered with Gengo to obtain high-quality annotated data to train deep-learning models such as those required by entity extraction software.
Counted on by companies like LexisNexis and Microsoft Bing, Basis Technology's Rosette Entity Extractor enables users to conduct unsupervised training on data to create personalized entity extraction models. For machine-learned models such as these, the accuracy and integrity of training data is paramount — any flaws or noise in the data negatively impacts performance of the model and its output.
Gengo's team of Japanese speakers annotated content using the brat rapid annotation tool, highlighting and marking named entities, and labeling them appropriately (organization, person, location, title, or product). This unconventional multilingual content project speaks to the flexibility and growing capabilities of the Gengo.ai platform.
The project was one of a series of trials that Basis Technology conducted with Gengo, which included:
1. Entity extraction in Japanese.
2. Sentiment analysis in Arabic.
3. Document categorization in English.
To gauge the performance of Gengo's services, Zachary Yocum, senior linguistic data engineer at Basis Technology, requested multiple trials to assess Gengo's data annotation capabilities. He concluded that Gengo's offering was indeed suitable for training and evaluating deep-learning models.
"For our projects, it's incredibly important to maintain a high level of data quality, otherwise it's garbage in — garbage out," Yocum said. "We used several internal tools to assess the quality of what Gengo provided, and the results were very good. We have confidence that we could potentially use the data for critical deep-learning projects."
"The fact that we delivered our billionth data point of complex language judgements speaks to the maturity of our tech platform and operational experience," said Charly Walther, VP of product & growth at Gengo. "As we expand our range of services from crowdsourced translation to include services such as labeling mission-critical data for machine-learning models, we are grateful to have strong partners like Basis Technology, who complement our linguistic crowdsourcing expertise with their in-depth knowledge of data requirements for NLP applications."
In recent weeks, in addition to the trials conducted for Basis Technology, Gengo.ai has provided other companies with an array of expert data services for machine learning, including:
- Data collection of handwritten Japanese characters by native speakers to train an OCR engine to read handwritten documents.
- Machine translation quality evaluation of Chinese to English sentences for retraining machine translation.
- For voice navigation software, the creation of an audio dataset consisting of hundreds of voice recordings of non-native Japanese speakers.
About Basis Technology
Verifying identity, understanding customers, anticipating world events, uncovering crime. Data is collected everywhere, all the time, in every language. For over 20 years, Basis Technology has provided the underlying analytical components to some of the largest and most difficult solutions that improve sales, reduce risk, and save lives. For more information, email info(at)basistech.com or visit http://www.basistech.com.
About Gengo
Gengo is a global, people-powered translation platform optimized for developers of multilingual applications. Founded in 2008, Gengo has delivered more than 1 billion words for 65,000+ customers. Gengo's professional human-powered translation platform represents a huge leap in quality compared to machine translation, and offers the fastest turnaround in the industry. Gengo is a privately held corporation based in Tokyo with offices in San Mateo (California), London, and Manila. To date, Gengo has raised $26M in venture funding from investors that include Intel Capital and Atomico. To learn more, visit https://gengo.com or follow us at @GengoIt.
SOURCE Gengo

Share this article